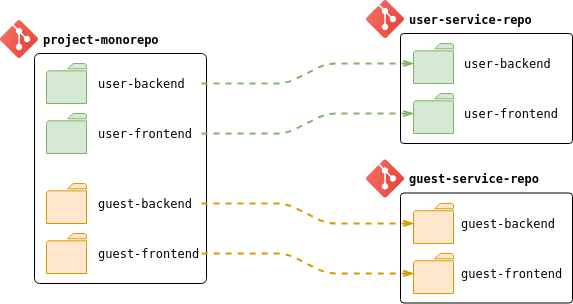
The Aspect-Oriented Programming paradigm allows to achieve a great level of Separation of Concerns (SoC) in the application’s codebase. All the necessary components that do not relate to the business logic directly, like security, metrics, logging, etc., can be nicely isolated into auxiliary modules that will be wired up with the business logic indirectly, usually during the compilation or in runtime.
In the Java world, there are not so many frameworks for AOP. The notable ones are AspectJ and Spring AOP. Both balance the complexity and functionality. The process of attaching the extra modules to the business logic is called weaving. In short, AspectJ supports compile-time weaving that modifies output class files (variation – post-compile weaving is used for 3rd party classes), and load-time weaving that intercepts the classloader and modifies the classes in the process of defining them to the JVM. Alternatively, Spring AOP has a much more simple model, it allows for runtime weaving only that works just for Spring Beans defined in the Application Context. The weaving is done via proxies generated by Spring.
In addition to these two frameworks, there is one more great library that exists for pretty similar objectives, it is called Byte Buddy, developed by Rafael Winterhalter. This library is pretty well known for its highly simplified and convenient facilities that allow runtime code generation and modification. Byte Buddy makes it easy to create a new type that can redefine existing types, intercept methods, and much more to that. But in addition, it can also change the behavior of existing classes. This is done via Byte Buddy Agent that can operate with Java Instrumentation API to do necessary changes to type definitions. This may sound similar to AspectJ load-time weaving, which in fact is, but practically there is a big difference between the two. The main benefit of using Byte Buddy is simplicity. The API is very intuitive, the extra tooling is not required, and overall integration of it does not force any changes in the build process, run configuration or so.
Now it is time to stop the theory and apply the Byte Buddy in practice. A simple, yet important example could be the detection of certain methods invocations. In fact, this idea has been inspired by the BlockHound project (detector of blocking calls from non-blocking reactive threads), developed by Sergei Egorov.
Leave a Comment