“organizations which design systems … are constrained to produce designs
which are copies of the communication structures of these organizations.”
M. Conway
Mono-repository in software development is a very popular way of organizing the source code and collaboration around it. It has some pros, like easy refactoring or dependency management, but it also has some cons, like a very high level of coupling between components (of course these statements are debatable but this is not the point of the current post). Some IT giants, like Google, Twitter or Facebook are still using mono-repository but this costs them quite a lot, just look at the new build systems like Bazel or Buck, they were invented to minimize the effort required to manage a huge pile of code.
At the same time, there is an alternative approach of making big products still having the projects distributed across multiple repositories. One of the benefits here is “loosely coupling” that leads to very easy scaling.
Practically not much of the projects are started already being split into modules and stored separately. In most of the cases it is a single repository that is growing until some point in time when the decision to split is made. But until this moment it is already a lot of work has been done. In case if the previous history is not relevant and can be neglected it is quite a simple task to make a split: move modules to the new location and tune CI accordingly. But in case if there is a need to preserve changes history and have it relevant to the content of each new module it becomes a non-trivial task, but (spoiler!) still possible to be performed quite fast.
Here is an abstract project with two logical modules: user-related and guest-related. Both are represented by four directories inside the repository. Ideal plan to separate those modules would be following:
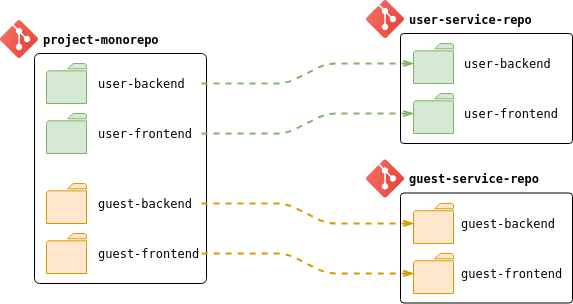
So, how to do this?
Leave a Comment